Daakaka dictionary
Background⇫¶
The language and its speakers⇫¶
This is a dictionary of the Oceanic language Daakaka. The language is spoken by approximately 1000 speakers in the West of the island of Ambrym, Vanuatu. It is used as the main language within families and villages of the region and is still acquired as a first language by most children in the region. However, it is not represented in any public or official contexts. There are efforts by the Vanuatu government and the research community to enable teachers to use local vernaculars as languages of instruction at primary schools, but these are still in their infancy.
Most speakers of the language are also fluent in Bislama, and have a good command of French or English, which are the main languages of instruction at school.
The data on which this dictionary is based was compiled by Kilu von Prince as part of a documentation project that ran from 2008 to 2012. The illustrations were created by Tio Bang. Prior to this project, the only written texts of the language were a few church songs probably composed by missionaries and text messages typed on mobile phones. Speakers of Daakaka are usually at least marginally literate in French or English and can also read Bislama.
For more information on the grammar of the language in general, see von Prince (2015a). For more information on nominal possession and nominal subclasses in particular, see von Prince (2015b). The corpus data on which the dictionary is based and from which many of the examples are drawn are available at The Language Archives (DoBeS corpora > West Ambrym languages > Daakaka).
Methodology⇫¶
The database is a result of my fieldwork on the language. This fieldwork was carried out between 2008 and 2012 as part of a documentation project on the West Ambrym languages, led by Manfred Krifka. Each year, I spent between three and four months on the island of Ambrym to record the previously undocumented languages Daakaka and Dalkalaen.
I transcribed my recordings with Praat and imported the transcriptions to SIL Toolbox. All transcriptions and translations were done in the field, with the help of various local consultants: Tio Bang, Krem of Emyotungan, Augustino Merané and Henri Merané. For every item in the transcriptions, I created a lexical entry. I elicited additional information to determine the lexical class and get a better understanding of the meaning. I would first ask consultants if they could use the same word in a different sentence or context. This type of elicitation was, however, only feasible with some consultants, while others would be stumped by the request. I would then try to come up with plausible uses of each item as a predicate, attribute, argument and so on, and elicit judgements about these example sentences. In the dicitionary, there are now two types of examples:
-
those whose reference number is prefixed by
xv.were added during fieldwork and are either elicited or abridged versions of sentences from the corpus. -
examples with a four-digit reference number without a prefix were added later from the corpus. I added these examples in particular to the most frequent items.
In addition to the entries that came from the recorded texts, I also elicited lists of words using various methods. For the very first elicitation, I used the common Swadesh list, with some adaptations to the local environment. I used compilations of pictures showing local fauna and flora, in particular the compilations of photos in Kahler (2007b) and Kahler (2007a). Gowers (1976) shows black and white drawings of local plants, which I also used; however, the drawings were harder to identify for locals, presumably because of the rather unfamiliar mode of presentation.
I found that a productive and quite enjoyable way of eliciting words was simply to prompt speakers during dinner time, while everyone was gathered in the kitchen hut, to come up with more items belonging to a certain semantic field. Many of the items for insects and bodily functions, to name just two semantic domains, have originated this way.
Aim and scope⇫¶
The lexical database for this dictionary was not compiled with a single purpose in mind, but was rather designed for the derivation of several different types of materials. It was at first primarily used as a tool for the annotation and analysis of transcribed recordings.
Another important purpose of the database was the production of illustrated dictionaries for local use. For this purpose, native speaker and artist Tio Bang created beautiful black-and-white illustrations. This also means that all entries are supplemented with translations to the national language Bislama and elicited examples are also translated to Bislama as well as English.
Finally, I wanted to reserve the option of publishing the dictionary for a general and academic readership. This is why I added encyclopedic information to culture-specific concepts, scientific names for plants and animals (where possible) and similar.
Conventions⇫¶
Structure of entries⇫¶
Every entry contains minimally a lexeme and a translation to English, either in the gloss field or in the definition field. Information on word class affiliations is provided for almost all entries. Not all entries are disambiguated into more specific subclasses – for example, verbs will be labeled as v, and only in some entries will this label be more specific such as v.tr for fully transitive or semitransitive verbs and v.itr for intransitive verbs. A list of part-of-speech abbreviations is given in the table below. More information on word classes in Daakaka can be found in von Prince 2015a.
| adj | adjective |
| adj1 | adjective of class 1 |
| adj2 | adjective of class 2 |
| adv | adverb |
| aux | auxiliary |
| comp | complementizer |
| contr.ptcl | contrast-sensitive particle |
| dem | demonstrative |
| gram | unique grammatical morpheme |
| intj | interjection |
| n | noun |
| n.rel | relational noun |
| n.rel.b | inflected relational noun |
| num | numeral |
| poss.pron | possessive pronoun |
| poss.suf | possessive suffix |
| prep | preposition |
| pron | pronoun |
| q | quantifier |
| qu | interrogative |
| res | resultative |
| sbj.agr | subject agreement |
| tam | tense, aspect, mood |
| v | verb |
| v.itr | intransitive verb |
| v.tr | transitive verb |
| v.tr.b | inflected transitive verb |
Except for entries that are transparent loan words from Bislama, a translation to this language is also given, in the definition field. In addition, there is a variety of other fields that are used only for some entries, such as one for encyclopedic information in English or semantic domains, on which more in the following section. A comprehensive list of fields and their description is given in the table below.
| lemma |
| part of speech |
| meaning dexcription |
| semantic domain |
| Bislama (meaning description) |
| lexical citation form |
| usage |
| etymological source |
| encyclopediv information |
| etymology |
| paradigm |
| scientific name |
| 1st person singular |
| 2nd person singular |
| 3rd person singular |
| 3rd person dual |
| dialectal variant |
| reduplicated form |
| comparison meaning |
| see also |
| synonym |
| antonym |
Abbreviations⇫¶
The dictionary contains various types of abbreviations. Apart from the abbreviations for part-of-speech categories described above, there are also abbreviations for functional glosses, such as 1d.ex for ‘first person dual exclusive’. A full list of these abbreviations is given in the table below. There is one group of abbreviations in this list that warrants special comment here: A number of lexemes in the database are glossed as a combination of em, followed by person-number information as in em.2s; this stands for ‘emotive, second person singular’. This is a class of lexemes where an inflected noun has fully merged with the person-number inflection so that they can no longer be separated. They are also semantically bleached in that they only exist as subjects of certain emotion verbs such as nek ‘be afraid’ as in the following example:
They etymologically derive from the inflected noun for ‘skin’, as can still be seen in related lexemes from neighbouring varieties and the first-person form ul-uk, which could be literally translated as ‘my skin’. For more on expressions of emotions in Daakaka, see von Prince (submitted).
| 1d.ex | first person dual exclusive |
| 1d.in | first person dual inclusive |
| 1d.in.poss | first person dual inclusive possessive |
| 1pl.ex | first person plural exclusive |
| 1pl.ex.poss | first person plural exclusive possessive |
| 1pl.in | first person plural inclusive |
| 1pl.in.ob | first person plural inclusive (object) |
| 1pl.in.poss | first person plural inclusive possessive |
| 1pl.in.sb | first person plural inclusive (subject) |
| 1pc.ex | first person paucal exclusive |
| 1pc.ex.poss | first person paucal exclusive possessive |
| 1pc.in | first person paucal inclusive |
| 1sg | first person singular |
| 1sg.poss | first person singular possessive |
| 2d | second person dual |
| 2d.poss | second person dual possessive |
| 2pl | second person plural |
| 2pc | second person paucal |
| 2pc.poss | second person paucal possessive |
| 2sg | second person singular |
| 2sg.poss | second person singular possessive |
| 3d | third person dual |
| 3d.poss | third person dual possessive |
| 3pl | third person plural |
| 3pl.dem | third person plural demonstrative |
| 3pl.dem.prox | third person plural demonstrative proximal |
| 3pl.poss | third person plural possessive |
| 3pc | third person paucal |
| 3pc.poss | third person paucal possessive |
| 3sg | third person singular |
| 3sg.poss | third person singular possessive |
| al.sg | attributive linker, singular |
| al.pl | attributive linker, plural |
| asr | assertion marker |
| cl1 | possessive classifier one |
| cl3 | possessive classifier three |
| comp | complementizer |
| cont | continuos aspect marker |
| cop | copula |
| cos | change-of-state marker |
| def | definite article |
| dem | demonstrative |
| dem.dist | demonstrative, distal |
| dem.prox | demonstrative, proximal |
| dim | diminutive |
| disc | discourse marker |
| dist | distal |
| doo | TAM-marker doo (‘whether’) |
| em.1sg | emotive, first person singular |
| em.2pl | emotive, second person plural |
| em.2sg | emotive, second person singular |
| em.3d | emotive, third person dual |
| em.3pl | emotive, third person plural |
| em.3pc | emotive, third person paucal |
| em.3sg | emotive, third person singular |
| ep | epenthetic consonant |
| fut | future (potential) |
| instr | instrumental |
| intj | interjection |
| loc.dem | local demonstrative |
| med | medial distance |
| name | name |
| neg | negative |
| nom | nominalizer |
| pot | potential marker |
| place | place |
| real | realis |
| redup | reduplication |
| ref.pron | reflexive pronoun |
| res | resultative |
| top | topic marker |
| trans | transitivizer |
There are some other, general, abbreviations in the running text, which are listed in table [tab:abbr].
| e.g. | for example |
| lit. | literally |
| so. | someone |
| sth. | something |
| etc. | et cetera (and so on) |
Orthography⇫¶
The orthography used for the dictionary and examples follows the standards developed by myself and the Daakaka Language Committee. There were close to no written records of the language before that. Basic correspondences between orthographic and phonemic values are given in the tables below, which are from von Prince (2015a).
| Labio-velar | Labial | Alveolar | Velar | |
|---|---|---|---|---|
| Nasal | mw | m | n | ng [ŋ] |
| Stop | pw, bw | p, b | t, d | k, g |
| Fricative | v | s | ||
| Approximant | w | y [ʲ] | ||
| Trill | r | |||
| Lateral approximant | l |

For details on the orthography development, see von Prince (2015a).
Associated media⇫¶
The dictionary database is linked with a total of 60 illustration files. These are black-and-white drawings created by local artist and Daakaka speaker Tio Bang, who holds their copy-right.
Semantic distinctions between near synonyms⇫¶
Cutting verbs⇫¶
There are several verbs in the dictionary that are translated as variations of cut into English. The differences between them are hard to capture by simple translations. Many of those verbs are a combination of the two roots sye(wa) and ta(wa) with a resultative suffix.
The main difference between sye(wa) and ta(wa) is that the former is aprecise movement typically performed with a slender blade or scissors, whilethe latter is a rather imprecise hacking movement, often with both hands on a heavy blade. Both sye and ta contrast with more blunt means of disintegration, such as smashing something with a hammer.
These are preliminary conclusions which are based on an elicitation I did withone speaker based on the cut-and-break video clips developed by [Bohnemeyer et al., 2001]. The detailed results of this elicitation can be seen in table 6. Syep is an alternate form of sye in combination with resultative suffixes and serial verb constructions.
Tii means roughly ‘pierce’ with a needle or similar. Some other terms are rather more specific. For example, wulyakate means ‘peel’, in the context offruit, but also in the context of removing bark from a piece of wood with a knife.
The main resultative suffixes that combine with these verbs are kote ‘apart’; kuwu ‘out, away’; and tae ‘through’.
| Video | Response |
|---|---|
| cb01chands.mpg | mwe tyowa, mwe tae kaleko |
| cb02rpoint.mpg | tiikote |
| cb03stickontree.mpg | takote |
| cb04cfury.mpg | takote |
| cb05sfury.mpg | katiwiye |
| cb06carfury.mpg | takote |
| cb07opentable.mpg | saasaa metone |
| cb08cspont.mpg | kaleko ma |
| cb09carknifelong.mpg | syewa |
| cb10carslice.mpg | syep mwelili |
| cb11opencup.mpg | diskuwu |
| cb12cknife.mpg | syepkote |
| cb13raxe.mpg | takote |
| cb14mpartcut.mpg | syep yan melen |
| cb15ssaw.mpg | syepkote |
| cb16sspont.mpg | setyup |
| cb17carspont.mpg | sekur |
| cb18cutfinger.mpg | ma sye bokosin |
| cb19shands.mpg | katiwiye |
| cb20sknife.mpg | syepkote |
| cb21carhammer.mpg | tu(mi)milye |
| cb22openpen.mpg | diskuwu led ane pen |
| cb23chammer.mpg | tukote |
| cb24rscissors.mpg | syepkote |
| cb25spartcut.mpg | bwiti |
| cb26carknifeshort.mpg | syepkote |
| cb27hairscissors.mpg | sye vyun |
| cb28cutfish.mpg | syepkuwu baten myane gilyen |
| cb29openorange.mpg | wulyakate |
| cb30openbanana.mpg | wulyakate |
| cb31shammer.mpg | tu(mi)milye |
| cb32carkarate.mpg | tukote (ne vyan) |
| cb33openbook.mpg | sangave, wuo sangave |
| cb34ckarate.mpg | tukote |
| cb35rfury.mpg | dokokokote aua |
| cb36cpartbreak.mpg | mwe tae/ tyotae |
| cb37caraxelong.mpg | tawa |
| cb38rhands.mpg | dokokote |
| cb39pothammer.mpg | tuwa |
| cb40phammer.mpg | tuwa |
| cb41openbox.mpg | sengave |
| cb42skarate.mpg | tatiwiye ne vyaa |
| cb43carpoint.mpg | tiikote |
| cb44opencan.mpg | syokuwu led an, sangave |
| cb45cpoint.mpg | pastae, tiitae |
| cb46rspont.mpg | sekur |
| cb47openhand.mpg | mu wuo, mu sangave vyan |
| cb48saxe.mpg | takote |
| cb49rknife.mpg | syepkote |
| cb50rhammer.mpg | tukote |
| cb51msplit.mpg | tawa |
| cb52openmouth.mpg | banga |
| cb53spoint.mpg | tiikote |
| cb54caraxeshort.mpg | takote |
| cb55openpot.mpg | sangave |
| cb56cscissors.mpg | syepkote |
| cb57carhands.mpg | katiwiye |
| cb58openeyes.mpg | lye |
| cb59openscissors.mpg | sangave |
| cb60opendoor.mpg | sangave |
| cb61rkarate.mpg | takote ne vyaa |
Pluractionality⇫¶
A number of verbs have the same translation into English and differ primarily in whether they describe a singular event or a plural event. For example, gilye and puos both translate as ‘buy’, but gilye refers to an act of buying one individual item, while puos refers to an act of buying several items. There is a small list of verbs which come in such pairs, including mur and tesi ‘fall’ and liye and tilya ‘take; carry’.
Another domain which instantiates this difference are verbs for fighting and killing – compare singular tiye with plural tyup and with baa, which is not specified for number. Like Bislama kilim, these verbs do not differentiate between the act of hitting or kicking and the act of killing. They do also not differentiate between human and non-human patients.
The most productive method to talk about different ways of killing more specifically is to combine a verb with the resultative suffix -veni ‘to death’. Formore on pluractionality and resultative suffixes in Daakaka, see the chapter on verbs in [von Prince, 2015].
Semantic domains⇫¶
General⇫¶
Many entries are assigned to one or more semantic domain (\sd), such as fauna or climate. This classification serves various purposes. The immediate goal forme was to have a basis for a thematically organized dictionary for local useon Ambrym. The speakers preferred to have thematically structured sectionsrather than a purely alphabetic organization. For this reason, some of thecategories that I chose reflect locally relevant taxonomies and concepts ratherthan European ones. I will expand on the main characteristics of the taxonomies in Daakaka in the following section.
Even so, I hope that this information will also be helpful for internationalresearchers who seek to compare terms and vocabularies cross-linguistically withrespect to certain domains. For example, the coconut is a locally very importantplant, and a total of 28 terms referring to specific parts of the plant, stages ofgrowth, or activities related to it, have been assigned to the correspondingsemantic category. The list of those terms may be used for elicitations of other languages in the region that may possess corresponding lexemes.
Other semantic domains such as kinship and color concepts are also of broadtypological interest and have been tagged accordingly. It has to be said, though,that the kinship terms in particular are incommensurable with English andtranslations in the dictionary are thus by necessity very insufficient. For more on kinship and other specific semantic domains, see [von Prince, 2015].
Local taxonomies⇫¶
The semantic domain plants represents a European concept without a clearcounterpart in Daakaka terminology. In the terminology of [Berlin, 1973], thereis no term for a unique beginner covering all plants. Instead, plants are generally subdivided into plants with stalks (lee); plants with vines (aua); and grasses (barvinye), which may also cover tender shoots and similar.
There are some clearly identifiable hierarchically ordered groups, which couldbe visualized by a tree diagram such as in figures 2 and 3. The affiliation of a plant to either the group of lee or of aua is signaled systematically in the linguistic terms: Every plant which belongs to lee can be prefixed by the syllable lV-, where V is a vowel that depends on the root, as in lo-wotop (literally ‘plant of the breadfruit’). Vines, that is plants belonging to aua all start with an a.
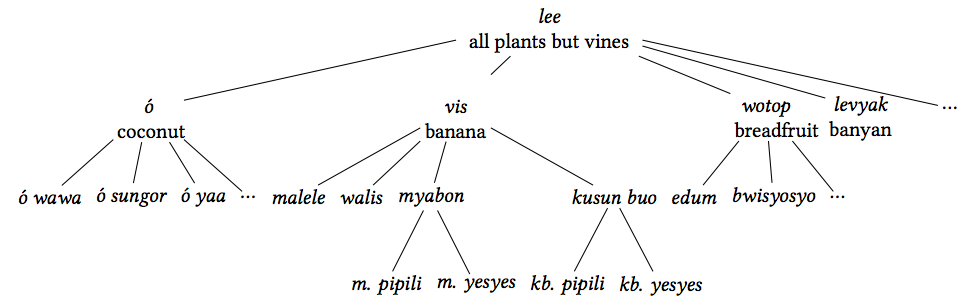
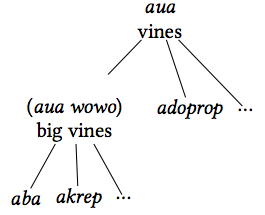
Subdivisions within these taxa can be inferred from the way people talk about the relations between them as in the following examples:
The realm of animals appears to be less structured than that. In the terminology of [Berlin, 1973], there are many generic taxa and some of them appear to be subdivided into varietal taxa. Thus, there are several kinds of snakes and spiders. To the extent that there are terms which cover a large and diverse group of animals, these terms do definitively not match with Western taxonomies.
A very good example for this is the term baséé. I gloss it as ‘bird’, and I think that birds are the most prototypical cases for baséé. But this is not what the term actually means. Rather, the term baséé covers all animals that can fly.
In the following example, it is clear not just from the terminology but alsofrom the comparisons, that the flying fox is grouped with other animals which can fly, be they butterflies or chickens.
Moreover, being a baséé does not appear to be a property that characterizesan individual across their entire life span. It may apply only to a certain stagein their life cycle instead. This is illustrated by the following explanation about the woodborer.
Acknowledgements⇫¶
I would like to thank the people of West Ambrym for their hospitality and their work with me. In particular, I want to thank chief Filip Talépu Bweangtan for sharing his great knowledge of the language and facilitating my work throughout the region. Donatien Kaingas Merané and his wife Catherine, of Sesivi, for their great commitment to help me understand their language and to keep me comfortable at all times; Tyo Maseng, for his immeasurably valuable input as well as the illustrations he provided; Seebu Esther Bweangtan for her detailed discussion and explanation of previous dictionary versions; and all the members of the Language Committee, consisting of chief Filip Talépu Bweangtan, Donatien Kaingas Merané, chief Ruben Byakmwelip of Yelevyak, chief Moses Emwele of Baiap, Andrew Tavi of Baiap, Augustino Merané of Sesivi and chief John Bongmyal of Baiap.
I would also like to thank Iren Hartmann, for her swift and constructive correspondence during the process of preparing the dictionary for publication. And Ulrike Mosel, Robert Forkel, Martin Haspelmath, and the participants of the dictionaria workshop in 2016 for their feedback and discussion.
The work on this project has been funded in part by the Volkswagen Foundation and by the BMBF (Federal Ministry of Education and Research).
References⇫¶
Berlin, B.. 1973. General principles of classification and nomenclature in folk biology. American Anthropologist, 75(1):214-242.
Bohnemeyer, J., Bowerman, M., and Brown, P.. 2001. Cut and break clips. In Levinson, S. C. and Enfield, N. J..editors. Manual for the field season 2001. pages 90-96. Max Planck Institute for Psycholinguistics. Nijmegen.
Gowers, Sheila. 1976. Some common trees of the new hebrides and their vernacular names. Port Vila, New Hebrides: Forestry Section, Dept. of Agriculture.
Kahler, Jessica S. 2007a. Local language picture dictionary. marine environment & animals. US Peace Corps Vanuatu.
Kahler, Jessica S. 2007b. Local language picture dictionary. terrestrial & river animals. US Peace Corps Vanuatu.
Prince, Kilu von. submitted. Dozing eyes and drunken faces: Nominalized psych-collocations in Daakaka. Studies in Language
von Prince, Kilu. Daakaka, the language archive.
von Prince, Kilu. 2015a. Alienability as control: the case of Daakaka. Lingua.
von Prince, Kilu. 2015b. A grammar of Daakaka. Berlin, Boston: De Gruyter Mouton.
| Full Entry | Headword | Part of Speech | Meaning Description | Semantic Domain | Examples | |
|---|---|---|---|---|---|---|
| Full Entry | Headword | Part of Speech | Meaning Description | Bislama | Etymological Source | Encyclopedic Information |
|---|---|---|---|---|---|---|
| Primary Text | Analyzed Text | Gloss | Translation | IGT |
|---|---|---|---|---|