General Dictionaria Submission Guidelines and Best Practice Recommendations for Dictionary Entries
version of 9-1-2016
While the format of all Dictionaria dictionary publications will be a relational database, authors may also submit other (quasi-)database formats. We currently accept submissions in the following formats: .sfm, .db, .txt (e.g. from Toolbox, LexiquePro or FLEx), and .csv (e.g. exported from Excel or FileMaker). If you use a different format please contact us, so that we can see what we can do for you.
A Dictionaria submission must consist of an introductory text and two to four files containing the following datasets: entries, senses, examples, and references. These datasets can be represented in tabular form and will function as our database tables; therefore, the files must be related via IDs as described in the sections below. The dictionary submission may also contain sound files, video files and image files.
These Guidelines first describe the content structure of a submission, and then describe the quality standards. For some sections there will be some extra instructions for Toolbox/FLEx users, as we expect most contributions to reach us in that format, at least until new tools are established.
Even though most Dictionaria submitters will submit their data in a well-known technical format, these Guidelines here describe the content structure without regard to a format, because the eventual publication is independent of any software environment. Dictionaria provides a web application for viewing and searching, but each dictionary should be thought of as a structured relational database that consists of (up to) four data tables plus (optionally) multimedia content.
Overview: The six parts of the content structure ⇫ ¶
The most important principles of Dictionaria contributions, which distinguish them from many existing dictionaries, are:
- entries must not have subentries
- examples are optionally glossed as well as obligatorily translated, and are associated with senses, not entries as a whole
- multiple examples may be associated with one sense, and multiple senses with one (and the same) example (many-to-many relationship); one and the same example may illustrate the senses of different words
- Part 1: The introductory prose text (details in §1.1)
-
This text must consist of at least of the following sections:
- the language and its speakers (basic genealogical sociolinguistic and geographical information)
- the source of the data (information about texts and speakers and how the author had access to them)
- the orthography used in the dictionary (including a table mapping special orthographic symbols to IPA symbols)
- the kinds of special information contained in the dictionary, i.e. fields other than the obligatory fields and the other standard fields
- Part 2: The entry table (details in §1.2)
-
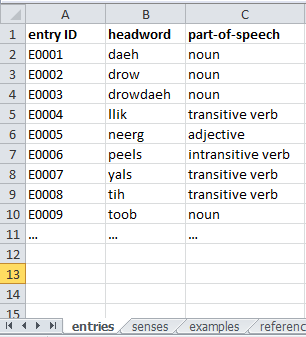
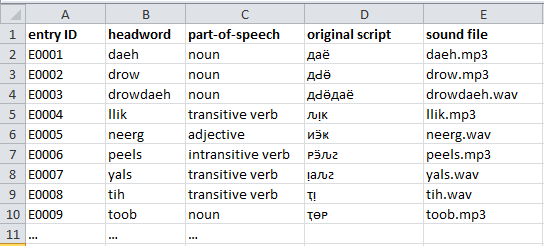
Screenshot 1. The entry table Each entry must contain information in the following three fields:
- (entry) ID (a unique alphanumeric code, chosen arbitrarily)
- headword (= lemma, or citation form)
- part-of-speech
In a simple wordlist, the entry table would also contain a field “sense”, but in more sophisticated dictionaries, an entry may have multiple senses. Thus, in Dictionaria there is a separate table containing the senses (Part 3 below). Authors must make sure that each entry has at least one sense linked to it.
In addition, an entry may have all kinds of further fields (see §3 below).
- Part 3: The sense table (details in §1.3)
-
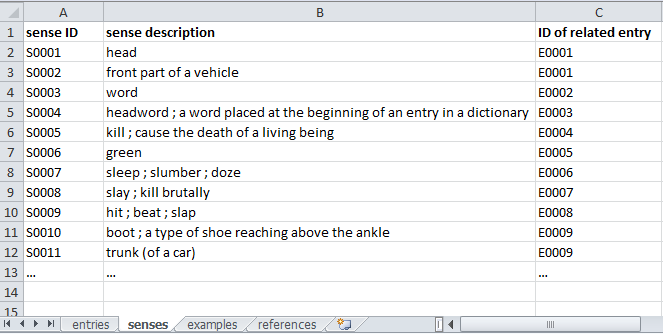
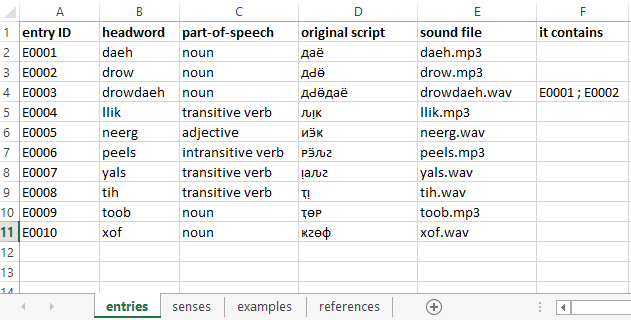
Screenshot 2. The sense table The sense table contains all the senses, which are represented in the dictionary. Each sense is linked to exactly one entry, but entries may have multiple senses linked to them (e.g. German spinnen 1. ‘spin’ 2. ‘be crazy’). There is thus a many-to-one relationship between senses and entries.
Each sense must minimally contain information in the following three fields (again, the ID is a code that can be chosen arbitrarily):
- (sense) ID
- sense description (= list of semicolon-delimited sense descriptors)
- ID of related entry
Since a sense may be illustrated by multiple examples, there is a separate table containing the examples (Part 4 below).
In addition, a sense may contain multimedia content, the field “semantic domain” and association fields relating to meaning (see §1.3 below), as well as comments and references fields.
- Part 4: The example table (details in §1.4)
-
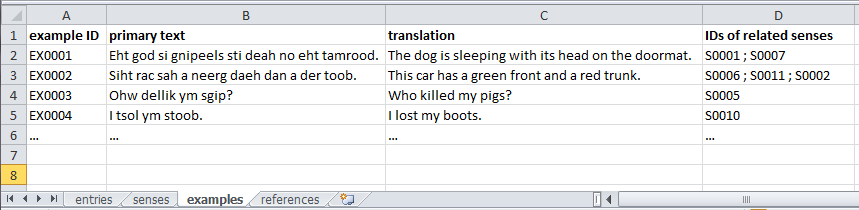
Screenshot 3. The example table The example table contains all the examples which are represented in the dictionary. Each example is linked to one or more senses, and senses may have multiple examples linked to them. There is thus a many-to-many relationship between examples and senses.
Each example must minimally contain information in the following four fields:
- (example) ID
- primary text
- translation
- list of IDs of related senses (this is a list, not a single ID, because an example may illustrate several senses)
In addition, there should be a field “interlinear gloss”, a field “example source”, and optionally also “analyzed text” (with morpheme-by-morpheme segmentations). There may also be other fields (see §1.4 below).
- Part 5: The references table (details in §1.5)
-
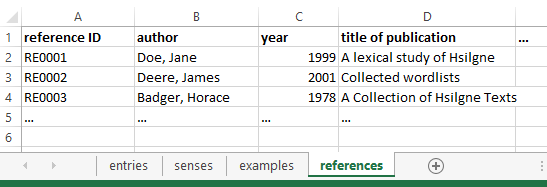
Screenshot 4. The references table A bibliographical reference must contain information on the standard bib fields:
- (reference) ID
- author
- year
- title of paper
- (and so on)
- Part 6 (optional): The media table (details in §1.6)
-

Screenshot 5. The media table A table containing further information about the included media files.
The introductory text ⇫ ¶
As noted in §1.1, the introductory text, giving background information on the language and the dictionary, must consist of at least four standard sections, discussed further in §1.1.1.-1.3 below. Further sections may be added (see §1.1.5.).
The language and its speakers
This section contains basic sociohistorical and geographical information on the language, including
- name of the language (possibly with discussion of other names that have been used elsewhere)
- ISO und Glottolog code
- names and codes of languages other than English that are used for sense descriptions and example translations
- genealogical affiliation
- approximate number of speakers, location of speakers
- social role of the language, multilingualism, literacy
- the most important earlier work by linguists and anthropologists on the language
Source of the data
It is very important for dictionaries of under-researched languages to give detailed information on the source of the data, so that the reliability of the data can be assessed and the input of speakers and assistants is acknowledged. In addition to giving the names of the people involved and their role, this section should also specify the times and places where the data were gathered, should give background information on the corpora that were the basis for the word collections, should list earlier or related dictionaries that may have been used, and possibly describe elicitation methods.
The orthography used in the dictionary
A dictionary should use a consistent orthography, especially for the headwords, regardless of whether the speakers use the language for writing or not. If the orthography uses non-IPA symbols (as will generally be the case), this section should contain a table mapping all orthographic symbols to IPA symbols.
If the language is normally written in a non-Latin script, this should also be given for each entry (and each form), but the headwords given in Latin script will be regarded as the primary representation.
This section may contain the alphabet (i.e. the ordered list of graphemes) used by the language, but it should be noted that any special sorting conventions will not be used in Dictionaria. (The sorting algorithm that is used is called DUCET, which is the default for Unicode characters.)
The section may also contain further discussion of the orthography, e.g. concerning its history, its specific properties, principles for word division, treatment of spelling variants, and so on.
Types of special information
This section lists the special fields contained in the dictionary, i.e. fields other than the obligatory fields and the other standard fields. For example, for some languages a dictionary might provide specific grammatical information (on inflection class, gender, classifier usage, etc.), other dictionaries might provide extensive information on spelling variants, dialectal variants or loanword provenance.
For each field with a restricted number of values, all values must be listed and described here (e.g. parts-of-speech, or semantic domains).
If any abbreviations are used, they also need to be explained here. However, in general the use of abbreviations is strongly discouraged, as abbreviations are far less necessary in electronic publication than in paper-based publication, as there are (almost) no space limitations
Additional sections
The introductory text may contain additional sections, e.g.
- further grammatical notes
- cultural notes
- explaining in more detail the expected use of the dictionary
- discussion of the size of the dictionary (number of entries, number of multimedia files, etc.)
- an acknowledgement section (e.g. listing native speaker assistants) at the end of the introductory text
The entry table ⇫ ¶
As noted in §1.1, each entry in the entry table must contain information in the following three fields:
- (entry) ID (a unique alphanumeric code)
- headword
- part-of-speech
The ID can be chosen arbitrarily, and in principle, it would be possible to use the headword as ID, with a distinguishing number when there are homonyms. For the purposes of the database, we need to keep the ID and the headword separate, so it is recommended to choose an arbitrary code (e.g. a number) as the ID.
The headword (or lemma) is the name of the entry. It is most often the citation form of a lexeme, but it may also be any inflected form such as went in English dictionaries, a root, an affix, or a multi-word expression (such as phrasal verbs, frequent or lexicalised collocations and idiomatic phrases).
The part-of-speech field contains information such as “verb”, “noun”, and for multi-word lemmas either simply „phrase“ or a language specific term such as „phrasal verb“ or „serial verb“ can be used. Language specific terms must be definted in the introduction..
Since an entry can have multiple senses, the entry table does not contain sense information, and there is a separate table containing the senses. For each entry, there must be at least one sense.
In addition, an entry may have all kinds of further fields, whether standard fields (which have the same meaning across languages) or language-specific fields (which are defined depending on the language’s system, or peculiarities of the culture).
Examples of standard fields are:
- lemma in original script
- pronunciation of lemma
- variant form
- general comments
- bibliographical references (list of bibref IDs)
- etymological origin
- source language (for loanwords)
- source word (for loanwords)
For sound files, images, and video clips there are separate fields
- sound file ID
Examples of language-specific fields are:
- gender
- inflectional class
- form in divergent dialect X
- sociolinguistic information such as literary vs. colloquial, obsolete, taboo, etc.
Finally, an entry can contain (standard or language-specific) association fields, i.e. fields that establish a relationship between the entry and some other entry. The content of an association field is a list of entry IDs. The name of an association field is relational, i.e. it is a transitive or copula verb or ends in a preposition, e.g.
- it contains (list of entry IDs)
- its causative is (list of entry IDs)
- its numeral classifier is (list of entry IDs)
- see also (for generally related entries)
Association fields are optional, but if a Dicitonaria contribution makes use of one or more of them, then we encourage the authors to do so in a consistent and comprehensive way.
Note that Dictionaria contributions must not have subentries; what would be treated as a subentry in a linear dictionary is treated as a separate (but associated) entry in Dictionaria.
Entries with multi-word lemmas such as take part would be associated with take and part via association fields (it contains (list of IDs)).
The sense table ⇫ ¶
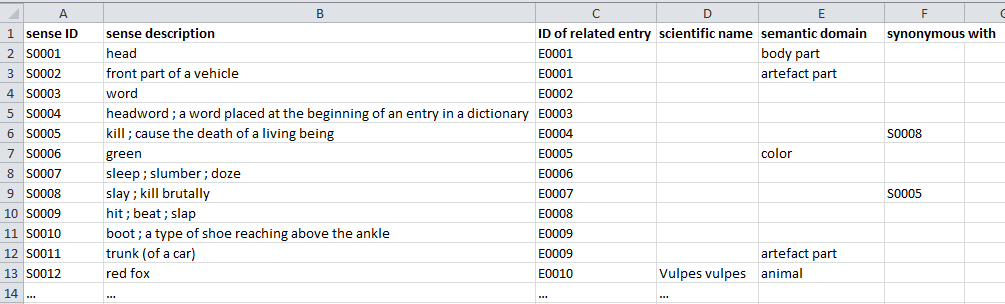
As noted in §1.1, each sense must minimally contain information in the following three fields:
- (sense) ID
- sense description (in English)
- ID of related entry
Since a sense may be illustrated by multiple examples and the words in one example may illustrate senses of different entries there is a separate table containing the examples.
The sense description (= definition) is a list of semicolon-delimited sense descriptors.which may be translation equivalents or explanations. They are semicolon-delimited because a sense descriptor itself could contain a comma (e.g. “big, expensive boat”).
In addition, a sense may contain the following standard fields:
- list of semicolon -delimited semantic domains
- scientific name (for plant and animal species)
- comments on sense
- bibliographical references (list of bibref IDs)
- sense description in the source language with a translation into the target language
Note that a “gloss” field, as used in Toolbox for glossing purposes, is not relevant for Dictionaria contributions.
Senses may also contain language-specific sense descriptions, especially descriptions in a major additional language spoken by many speakers (e.g. Spanish for indigenous languages of Mexico, Indonesian for languages of Indonesia, etc.):
- sense description in language X
Like entries, senses can contain fields for associated senses, e.g.
- is synonymous with (list of sense IDs)
- is antonymous with (list of sense IDs)
The example table ⇫ ¶

As noted earlier, each example must minimally contain information in the following four fields:
- (example) ID
- primary text
- interlinear gloss (not obligatory
- translation (into English)
- list of IDs of related senses (this is a list, not a single ID, because an example may illustrate several senses)
- source of example (initially not obligatory; bibliographical or corpus reference; name of speaker who provided the example)
In addition, there may be further standard fields (and perhaps also language-specific fields):
- analyzed text (e.g. morphemes, or more abstract morphophonological representation)
- literal translation
- date (of data collection)
The references table ⇫ ¶
A bibliographical reference must contain information on the standard bib fields (cf. the Generic Style Rules for Linguistics):
- (bibref) ID
- publication type (journal article, book, book part, thesis, misc)
- author list
- year
- article title
- editor list
- publication title
- volume number
- page numbers
- city
- publisher
Of course, different publication types use different subsets of these fields.
The media table ⇫ ¶
If your dictionary includes media files and additional information about them (e.g. comments, sources, descriptions), you need to also submit a media table. In this table the file names and their file extensions are listed (these serve as the media file IDs) in the first column. additional information can be added in the following standard columns:
- source (e.g. name of native speaker for audio recordings, photographer of a photo, illustrator of a drawing)
- source URL (if your file is also part of another web publication)
- description (e.g. if you want to describe what is shown in a picture)
The media table should be submitted in .csv format.
Dictionaria Submission Guidelines Commentary for Toolbox Users
version of 10/23/2016
If you are planning to submit a Toolbox database to Dictionaria, you will find these hints helpful. We strongly encourage you to first read our general submission guidelines thoroughly and then use these extra guidelines as a commentary. The Toolbox tips follow the outline of the general guidelines. For each section, that may be confusing to Toolbox users we will explain here what this means and entails for you.
All Toolbox submissions to Dictionaria should generally consist of a Dictionary text file (.txt, .db), an examples text file (.txt, .db) and their corresponding .typ files. If you are using the MDF 4.0 templates without any modifications or extra fields then you do not need to send in the .typ files. If you are using an orthography in one of your dictionary fields, which is not Latin based, and/or has special characters, then you need to also send us the associated .lng (Language encoding) file.
In addition to your Toolbox files, we ask you to also send us a prose description as described in §1.1 in the general guidelines.
Re: Overview: The six parts of the content structure ⇫ ¶
no subentries
We cannot accept submissions with subentries, as they do not fit into our general data model. If you have made use of the \se field in Toolbox, you need to go through each and every one of them and turn them into new entries. You may then use a reference field, such as \cf to link them to the original entry (see also “association fields” below). If you have made use of the \se field in a completely consistent way, you may contact us, as we may be able to help you in turning these subentries into new entries (semi-)automatically. This is only possible if your field structure is fully consistent and transparent.
What does this mean?
An entry like this:
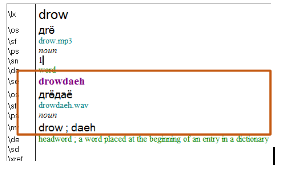
Will need to become two entries like so:

examples
Toolbox is set up to have example sentences stored directly in each dictionary entry. However, we strongly advise you to store example sentences in a separate text file instead and to simply list their sentence IDs in the dictionary entry. An advantage of keeping example sentences in a separate text file is that you can link them to different entries rather than copying them into several entries and thus risking inconsistencies. You can simply use the \xref field to refer to the corresponding \ref field in your examples text file. Another advantage of keeping your examples in a separate text file is that you may use Toolbox to help you parse and gloss them.
What does this mean?
Entries like the one here (using \xv and \xe):
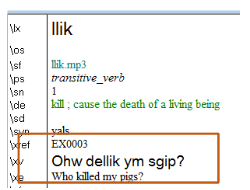
should look like this instead, with the example being stored in a separate text file (glossing is optional):

This way you can link one example sentence to several entries without creating inconsistent copies of one and the same sentence, e.g. in the entry below the same example can be listed as in the one above:

If you already have a Toolbox dictionary with example sentence, then please contact us, so that we can assist you in extracting them and storing them in a new text file (see also “Re: 5. The examples table” below)
(the rest of §1 does not need any further explanation here, as each topic is covered in a more detailed section later on the in the general guidelines)
Re: Overview: The entry table ⇫ ¶
This section describes what the entry table would look like in a relational database, as a Toolbox user you do not have a separate entry table, instead your dictionary file is a combination of the entry table and the sense table.
entry ID What does this mean?
The entry ID in Toolbox are the contents of the \lx field (in combination with the \hm field where necessary). You do not need to assign alphanumerical codes to your entries. In Toolbox your headword is the entry ID.
part-of-speech
To ensure consistency we strongly encourage you to use a range set in Toolbox for the \ps field. This will help you in avoiding typos or multiple abbreviations for one and the same thing. In fact, if possible do not use abbreviations at all. Do not use more than one \ps field per entry. If you have headwords which belong to two different word categories, you should create two entries.
media files
For media files (sound, images) simply use the Toolbox convention of listing the file name and its extension in the corresponding MDF field (\sf [sound file illustrating the headword], \sfx [soundfile of an example], \pc [picture]). You can then send us your files and we can then display them in your Dictionaria entries. If you also have videos you want to include, please contact us, and we will try to find a way to accommodate them.
association fields What does this mean?
What is called an association field in the Dictionaria submission guidelines also exists in Toolbox. Fields such as \cf or \syn are examples of such fields. If you have made use of association fields in Toolbox, you simply need to tell us which ones you have used, and what kind of association relation they represent. In these association fields the headwords to which your entry is related should be listed. You can also come up with your own association fields if necessary and use them in Toolbox (e.g. if you want to link inchoatives to their causatives, introduce a field called \caus and then list the related headword in it). Remember headwords are your entry IDs. If you have multiple entries to which an entry is related in one and the same way, you may list the associated entries in the same field separated by a semicolon. (E.g. if \lx drowdaeh is associated to \lx drow and \lx daeh, you may have an field \cf drow ; daeh)
Re: Overview: The sense table ⇫ ¶
As a Toolbox user you will not have a separate sense table. Your senses are part of your dictionary file. Sense descriptions should be given in the \de field.
entry ID What does this mean?
The sense IDs in Toolbox are the contents of the \de field. You do not need to assign alphanumerical codes to your entries.
multiple senses in an entry
If an entry has multiple senses, we strongly recommend that you use the sense number field (\sn) to indicate this. This will structure the entry much better than using two \de fields in a random place your entry. the \sn field should contain simply the number of the sense (1, 2, 3, etc.) and be followed by a de field. Look at the entry below, for a good illustration of sense numbering:

With the senses cleanly separated, you can also assign different semantic domains and different example sentences to each sense, as also illustrated in the screenshot.
Re: Overview: The example table ⇫ ¶
As already mentioned above, Toolbox is generally set up to list example sentences in the respective entries directly. This is where we at Dictionaria would like you not to follow the Toolbox conventions for the reasons stated above. If you have already created a database that includes example sentences then please get in touch with us so that we can help you in extracting them into a separate file while at the same time checking for inconsistences.
For your example sentences you can simply use a regular Toolbox Text file, with the common fields \ref, \tx and \ft. If you can also gloss your example sentences then use \mb and \gl as well.
Here is an illustration of what such an example sentence text file could look like:

With your dictionary being a scientific publication we also expect you to list sources for where your example sentence came from, this can either be a bibliographical reference, a corpus reference or the name of (or code for) a(n anonymized) native speaker of the language. In the screenshot above the \so (source) field has been used to store this information.
Re: Overview: The references table ⇫ ¶
We advise you to send us a list of references in a format that is not Toolbox. If you are already storing full bibliographical references in Toolbox then contact us and we will find a way to deal with it, but it is more advisable to send us a simple spreadsheet list of all full references and then to only list short versions or IDs to them of that in any Toolbox reference field.
What does this mean?
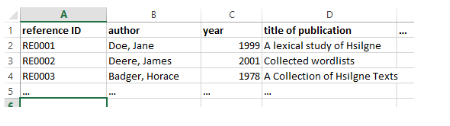
In the screenshot below an example sentence is listed as having a source RE0001:

This reference can be retrieved from a spreadsheet which follows the general submission guidelines like so:
✉ dictionary.journal@uni-leipzig.de
Best practice recommendations for dictionary entries
version of 5-4-2018
Headwords ⇫ ¶
Definition
A headword is the heading of a lexical entry. It either consists of an orthographical word, a sequence of orthographical words, so-called Multi-Word-Expressions (MWEs), a clitic, or an affix.
Conventions in Dictionaria
The dictionaries published in Dictionaria do not have subentries and, consequently, no sub-headwords. Therefore, we suggest to include different types of headwords:
- The most user-friendly form of the headword is the conventional citation form used by the speech community, rather than a stem form or a root, therefore it should be included at any rate.
- Roots or stems can additionally be included as headwords, if their entries have association fields linking the entry to the relevant derived or inflected forms used as the conventional citation form as stated in (1).
- In addition to the citation form, any irregularly inflected forms are also useful to have as headwords.
- The headword field itself should not contain variants. Rather, the variants should be treated as separate headwords and cross-referenced. Alternatively you may include a field in your micro-structure listing variants, but then these variants cannot be searched for as easily.
- Affixes and clitics can be distinguished by ‘-’ and ‘=’, respectively, e.g. =m (short form of am in English; -ed 1. past-tense suffix, 2. past participle suffix. We recommend that each dictionary contain all inflectional and derivational morphemes known in the language as headwords.
- If the headword is a multi-word expression, the component words should, if possible, be headwords as well. For example, if the dictionary has the headword light year, it also should have the headwords light and year. Ideally, the entry would then also show the glossing of the multi-word expression.
Parts-of-speech in Dictionaria ⇫ ¶
The drop-down box
In the main Dictionaria “Words” tab view, parts-of-speech can be accessed via a drop-down box, which requires a user-friendly size of the inventory of parts-of-speech, depending on the intended type of users.
Single-word headwords
We recommend using the part-of-speech field for major word classes of content and functional words, and use standard abbreviations, such as e.g.
- ADJ: adjective
- ADV: adverb
- DEM: demonstrative
- N: noun
- PREP: preposition
- PRON: pronoun
- V: verb
Subclasses such as simple noun or valency classes can be indicated by a single additional letter or numeral, for example:
- N.F, N.M, N.N: for feminine, masculine and neuter nouns
- N.1, N.2, N.3, ...: for numbered noun classes
- V.I, V.T, V.D: for intransitive, transitive, and ditransitive verbs.
Class and subclass information should be separated by a period.
Irregulary inflected forms can then be assigned to the same category as their citation form. Their specific meaning can be explained in the meaning description, cf. the German past tense form of gehen ‘to go’:
- ging v.i went; irregular past tense form. See: gehen ‘go’.
Multi-word expressions (MWEs) used as headwords
If it is impractical to classify MWEs on the basis of grammatical criteria, simply use the abbreviation MWE in the part-of-speech field. Otherwise, use transparent abbreviations for the type of MWE, for example:
- adj.constr adjectival construction, i.e. a construction that can substitute an adjective in the formation of a clause.
- n.constr nominal construction, i.e. a construction that can substitute a noun in the formation of a clause.
- v.constr verbal construction, i.e a construction that can substitute a verb in the formation of a clause.
Details of the composition of the construction can be given in an adjacent "structure" field, see Table 1.
| headword | part-of-speech | structure | meaning |
|---|---|---|---|
| benoo beera | adj.constr | n - adj | having a lot of meat |
| kapa kikis | adj.constr | n - adj | having a strong skin |
| hua hiava | vi.constr | vi - vi | paddle to the deep sea |
| hua hiava ni | vt.constr | vi - vi - appl | use something for paddling to the deep sea |
| paku kave | vi.constr | vt - n | make fishing nets |
Ideally, the construction field is also complemented by a field of morphological segmentation and a field of glossing:
hua hiava ni
paddle go.up APPL
Clitics
If a clitic is a variant of a phonologically independent headword, it is classified in the same way. Typical examples are clitic pronouns, articles, auxiliaries, or tense-aspect-mood particles. Otherwise it is simply classified as “clitic”.
| language | headword | part-of-speech | meaning description |
|---|---|---|---|
| English | =m | vi | short form of am; 1st person singular present tense of be |
| French | l= | article | short form of le; definite singular masculine article le |
| Latin | =ne | particle | interrogative particle |
Affixes
The part-of-speech assignment of affixes is based on their position, i.e. they are categorized as prefix, infix, transfix, or suffix; the English headword -s would, for example, have the part-of-speech: suffix.
Meaning descriptions ⇫ ¶
Definition
The meaning description contains translation equivalents, explanations, or descriptions.
Conventions
Meaning descriptions do not start with capital letters (unless they begin with a proper name) and do not have a period at the end.
Monosemy and polysemy of content words
With the exception of internationally defined terminologies, the meanings and usages of the source language (SL) and target language (TL) words rarely fully match. The fact that a SL word has two or more translation equivalents does not imply that it is polysemous. The SL word may be monosmous and denote a concept that is not expressed by any single TL word (Evans 2011:522-528). In this case the translation equivalents should be treated as belonging to a single sense, if the purpose of the ULD is to document the semantics and the usage of SL lexical items rather than to serve as a tool for rapid translation.
As evidence for polysemy and consequently, as a justification of sense division one counts distinct grammatical and collocational features which should be illustrated by examples.
Problematic translation equivalents
If a translation equivalent is polysemous or homonymous, it should be accompanied by an explanation. For example, mere translation equivalents like ‘back’ are not sufficient, because the English word back has several senses, for example,
- ‘back (of a person)’
- ‘back (opposite of front)’
which in many languages are denoted by distinct lexical items.
If the SL headword has a narrower meaning than its translation equivalent, this restriction can be indicated by parentheses at the beginning of the meaning description, e.g. the English meaning description of German fressen would be ‘(of animals) eat’.
Grammatical affixes and function words
The grammatical categorization of affixes and function words are put in square brackets, e.g. [first person dual inclusive pronoun]. This convention facilitates the search for all grammatical meaning descriptions by a single click, when you search for “[“ in the meaning description field.
Examples ⇫ ¶
The function of examples
In documentary ULDs authentic examples prove the existence of the lexical items functioning as headwords and, as in other dictionaries, they complement the information given by the meaning description because they show how the lexical item is actually used in context (Kosem 2016:90). The examples must not be invented by the lexicographer (Hanks 2013:3-5, 21, 307-310). The sources of the examples must be explained in the dictionary information; ideally, the source of each example is stated together with the example in the entry.
For the properties of good examples see Mosel forthcoming §2.5.4 and the literature quoted there (LINK to article).
The translations of examples
All examples must have a translation. If the construction of the free translation is very different from that of the SL, an additional literal translation will help the user to understand the structure of the example. The translation may also contain information put into brackets about the context. Idiomatic expressions should also always be accompanied by a literal translation.
If the citation of a sentence from the text corpus is too long to be user-friendly, it may be shortened as long as the relevant construction is not affected.
Ideally, the examples are also morphologically segmented and glossed.
Semantic domains /semantic fields (optional) ⇫ ¶
Definition
Semantic domains consist of semantically related lexical units and are independent of parts-of-speech. The semantic domain of cooking may, for instance, comprise verbs denoting processes and actions as well as the names of tools. A headword can belong to more than one semantic domain; the English word potato could, for instance, be assigned to the semantic domains PLANTS and FOOD.
Purpose
In an e-dictionary of an under-resourced language of a few thousands entries, the list of semantic domains is necessary to show the user its content. In Dictionaria the semantic domains are listed in a drop-down list. If, for example, you click FISHES in the Teop Encyclopedic Dictionary of Marine Life and Fishing, you see that the dictionary contains 159 fish names, but if you search the drop-down list for KINSHIP, you'll see that this semantic domain is absent.
Types of semantic domains
Typical semantic domains are taxonomic groupings and partonomies (Evans 2011:517):
- a superordinate concept that comprises subordinate concepts of the same kind of entity, event or property, e.g.
- pig, eagle, turtle, frog, tuna, wasp, beatle denote a kind of ANIMAL
- butcher, cut, chop, carve, slice denote a kind of CUTTING
- the concept of a whole, that consists of several parts of different kinds, e.g.
- HOUSE: roof, thatch, ridgepole, wall, door, window
- TREE: branch, twig, leaf
- the concept of SPACE, e.g. top, front, back, inside, in, under, behind, above, etc.
Selection of semantic fields
Since “there is no real consensus on what constitutes a semantic field or semantic domain, nor how it can be identified” (Majid 2015:366), Dictionaria leaves the selection of semantic fields to the dictionary compilers. There are several lists of semantic domains on the internet (see the references below). Do not blindly copy them, but critically select those that are adequate for your dictionary. Only have one level of categories, no subcategories. For headwords that are difficult to classify have a category "unclassified".
Websites for semantic domains:
http://www.anu.edu.au/linguistics/nash/aust/domains.html (accessed 02.04.2018). A collection of lists of semantic domains, put together by David Nash
http://www.ausil.org.au/node/3717 Most Austrlian -Aboriginal dictionaries found on this website have a drop-down list for semantic domains called "categories. (accessed 02.04.2018)
http://semdom.org/book/export/html/ This is the website for semantic domains used by the Summer Institute of Linguistics, (accessed 02.04.2018)
http://wold.clld.org/meaning . Semantic domains of thhe World Loanword Database (WOLD) (accessed 02.04.2018)
References
Evans, Nicholas. 2011. Semantic typology. In Jae Jung Song (ed.) The Oxford Handbook of Linguistic Typology. Oxford: OUP, pp. 504-533.
Hanks, Patrick. 2013. Lexical analysis. Norms and exploitations. Cambridge, Mass./London: MIT Press.
Kosem, Iztok. 2016. Interrogating a corpus. In Philip Durkin (ed.). The Oxford handbook of lexicography. Oxford: OUP, pp. 76-93.
Majid, Asifa. 2015. Comparing lexicons cross-linguistically. In John R. Taylor (ed.). 2015. The word. Oxford: OUP, pp.364-379.
Mosel, Ulrike. Forthcoming. Dictionaries of under-researched languages. In A Course Book on Foundational Skills, edited by Firmin Ahoua, Dafydd Gibbon and Stavros Skopeteas.
Munro, Pamela. 2002. Entries for verbs in American Indian language dictionaries. In William Frawley, Kenneth C. Hill & Pamela Munro (eds.). Making dictionaries. Preserving Indigenous Languages of the Americas. Berkeley, Los Angeles, London: University of California Press, pp. 86-107.
Pulte, William & Durbin Feeling 2002. Morphology in Cherokee Lexicography. In William Frawley, Kenneth C. Hill & Pamela Munro (eds.). Making dictionaries. Preserving Indigenous Languages of the Americas. Berkeley, Los Angeles, London: University of California Press,60-69.
Hinton, Leanne & William Weigel 2002. A dictionary for whom? Tensions between academic and nonacademic functions of bilingual dictionaries. In William Frawley, Kenneth C. Hill & Pamela Munro (eds.). Making dictionaries. Preserving Indigenous Languages of the Americas. Berkeley, Los Angeles, London: University of California Press, 155-170.